Note: You can now subscribe to my blog updates here to receive latest updates.
A typical kdb+ architecture (in a market data environment) is composed of multiple q processes sharing data with each other. These processes usually are: feed handlers, ticker plants, real-time subscribers (rdbs, pdbs, bars etc), historical databases (hdbs) and gateways.
Here is what the architecture looks like:
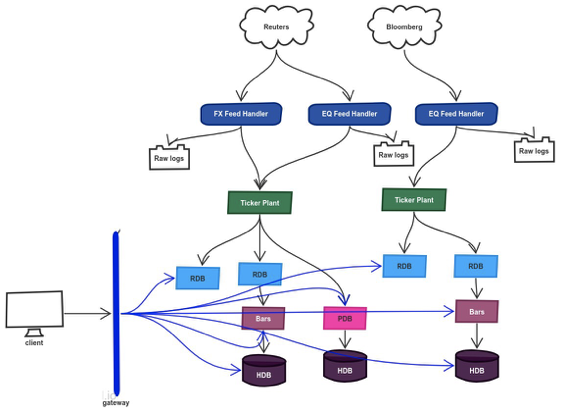
While this is a popular architecture which has been deployed in many production environments, it does come with some challenges:
- lack of pub/sub messaging – there is no native pub/sub messaging pattern built into kdb+. While q processes can publish data to multiple other q processes, this isn’t really pub/sub where you want to publish the data only once. This becomes more important as you scale and add more consumers.
- slow consumers – if one of the downstream applications is unable to handle data load, it can negatively impact your ticker plant and other downstream processes.
- data resiliency – what happens if the bar stats process in the architecture above crashes due to heavy load or network/equipment failure? How will your applications failover? Will the data in-flight be lost?
- sharing data with other teams – while kdb+ does have APIs available for different languages, kdb+ developers still have to implement and support these individual APIs internally.
- tightly coupled – the above architecture is very tightly coupled where it can be difficult to modify and deploy one process without impacting all others.
- cloud migration – as companies expand to the cloud, there is a need to transmit data securely to processes (written in q or another language) in the cloud.
- lack of guaranteed delivery – when dealing with critical data such as order/execution flow, you want to guarantee that the published data was consumed by interested consumers.
What is Solace PubSub+?

Recently, Kx released Solace interface for kdb+ which will bring the capabilities of pub/sub messaging to kdb+ and much more! For those who don’t know, Solace has been serving the financial industry with its industry-leading event broker, PubSub+, for almost two decades. PubSub+ can be deployed in three different ways:
- appliance – popular for high-throughput/low latency scenarios such as market data distribution
- software – easy to deploy as a docker container or machine image on-prem or on cloud. Standard Edition is free to use even in production.
- cloud – managed service with support for deployment in popular public clouds such as AWS, Azure and GCP. There is a free tier available!
If you are looking to try PubSub+, I highly recommend trying the free tier on PubSub+ Cloud. With a few clicks, you will have a PubSub+ instance running.
How can PubSub+ help kdb+ developers?
PubSub+ is loaded with tons of advanced features kdb+ developers can start leveraging right away. Here are some of the ways PubSub+ solves the challenges mentioned above:
- efficiently distribute and consume data – with PubSub+, kdb+ developers can use pub/sub messaging to efficiently fanout kdb+ updates at scale to both your front end and serverside applications. For example, q processes only need to publish data once and all other processes and clients can subscribe to the data they are interested in.
- slow consumers – PubSub+ has been specifically designed to handle slow consumers in such a way that they do not impact the performance of publishers or fast consumers.
- data resiliency – kdb+ developers can use guaranteed messaging to ensure delivery of messages between applications even in cases where the receiving application is offline, or there is a failure of a piece of network equipment.
- super easy integration – PubSub+ supports a variety of open APIs and protocols which makes it extremely easy for applications to interact with PubSub+. Forget having to manage all the APIs yourself, simply publish data to PubSub+ and downstream applications can use one of many available APIs to consume that data.
- decoupling q processes – instead of having your q processes talking to each other directly in a tightly coupled manner, you can have them share data through PubSub+. This will help decouple your processes and allow you to deploy code faster.
- replay – PubSub+ comes with a powerful replay feature that allows you to replay your messages hours or days after their original delivery. You can choose to replay messages delivered to specific topics only. (Note: this only applies to messages delivered via Guaranteed Message delivery)
- cloud migration – PubSub+’s Event Mesh allows brokers in different environments and regions to be linked together dynamically. With Event Mesh, you can have a q process publish data to PubSub+ broker deployed on-prem, link the broker to another PubSub+ broker deployed on the cloud, and have a different process consume that data locally in that cloud.
As you can see, PubSub+ brings a lot of advantages to your powerful kdb+ stack. Additionally, with PubSub+ being free to use in production, there is no excuse to not use it. I highly recommend checking it out!