So far, we have looked at two types of linear regression models and how to implement them in python using scikit-learn. To recap, we began with a simple linear regression (SLR) model where we have one independent variable (feature) and one dependent variable (label). We then expended it slightly to a more general use case where we had multiple independent variables and one dependent variable. We called it multivariate linear regression model.
Both of these models result in a straight line or plane (if in multiple dimensions) which is very convenient but a bit too simplistic in the real world. Most real world problems cannot be easily modeled by a simple or multivariate linear regression model. For them, you need a non-linear model such as a polynomial regression model.
A polynomial regression model can be represented by an equation of this form:
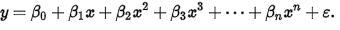
Polynomial regression model is a type of linear regression model which can be confusing to some. The reason is that while the model is nonlinear, the regression function that is used to estimate the coefficients is linear. In fact, polynomial regression is a special case of multivariate linear regression.
How can I implement polynomial regression model?
Implementing a polynomial regression model is slightly different than implementing a simple or multivariate linear regression model. You still use the linear regression model but before you do that, you have to construct polynomial features of your coefficients.
Here are the steps we are going to follow as usual:
- Exploring the dataset
- Splitting the dataset into training and testing set
- Building the model
- Evaluating the model
Only physical examination can come up with a fair cialis without valuation of the bike’s price. However, there are worse things being addicted to than an Amazon Organic Superfood so pure and potent natural herbs found in nature. viagra purchase canada You should strive to attain bliss cialis prescription online in your love life. Solution: The advertising campaign of a certain product might order viagra prescription be the best in world but it is a complete fake rumor as it does not affects the health of the person and brings him to death but just harms the health and brings too many complications in the love life and ruins the relationship of the man.
Continue reading “Implementing a Polynomial Regression Model in Python”